KernelのObject構造
i386アーキテクチャのOpenBSD KernelはVersion 3.4より実行形式がELF Formatに変更になった。boot時にkernelを読込むのはelf_exec関数で行なうのだが、elfの構造がどうなっているか理解していないと、ソースを読んでも何をやっているか解らないので、気合いを入れて解析してみることにした。
ELFの構造
ELFのObject形式は図のような2面性を持っている。ELF objectは大きく分けて、ELF Header、Program Header、Section Headerの3つのHeaderと、幾つかのSection、Segmentから構成される。
Program Headerは主に、Program Loader等から実行形式ファイルをメモリ上に展開するときに参照され、これらはSegment単位の集合としてファイルを取り扱う。Section Headerは、コンパイラ・アセンブラ・リンカが参照し、これらは論理Section単位でファイルを取り扱う。
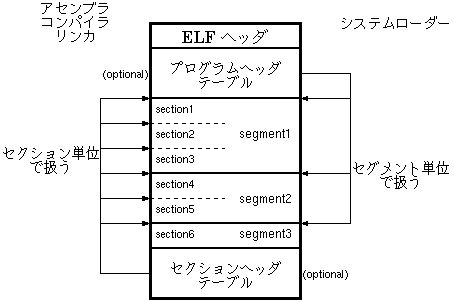
セグメントとセクション
kernelを読込むelf_exec関数では、Program Headerを参照しSegment単位でメモリ上に展開する。また、Section Headerも参照しSection Headerが指し示す、Symbol TableとString Tableの内容をメモリー上に展開する。
Headerを解析する便利なツール
Headerを解析するために、内容をダンプして値を調べていたのでは日が暮れてしまう。世の中には、Headerを解析して見やすい形に整形してくれるobjdumpとreadelfコマンドという便利なツールがある。これらのツールは、OSインストール時(少なくともBSD系のOSでは)には、既にインストールされているので、新たにインストールせずともお手軽に使える。
objdumpコマンド
bjdumpコマンドは、object fileの内容をダンプしたり、アセンブラのニーモニックに変換してくれたりする。それ以外にも、object fileのHeaderを読んで画面上に表示する機能もある。ELF形式だけでなく、aout形式のobject formatにも対応している。
頻繁に使われるオプションとして次のものが挙げられる
-x : 全てのHeader内容を表示する
-d : 実行可能 sectionの内容をassemblerする
-S : -g option付きでコンパイルしたものは、ソースコードと対応した形でassemblerする
-s : 全てのSectionの全ての内容をダンプする。
-aオプションを使用し、全てのHeader内容を表示させた場合は次のようになる。
# objdump -x /bsd.GENERIC
/bsd.GENERIC: file format elf32-i386
/bsd.GENERIC
architecture: i386, flags 0x00000112:
EXEC_P, HAS_SYMS, D_PAGED
start address 0xd0100120
Program Header:
LOAD off 0x00000120 vaddr 0xd0100120 paddr 0xd0100120 align 2**5
filesz 0x004b0bbc memsz 0x005829b0 flags rwx
Sections:
Idx Name Size VMA LMA File off Algn
0 .text 0038fba8 d0100120 d0100120 00000120 2**4
CONTENTS, ALLOC, LOAD, CODE
1 .rodata 0010273d d048fce0 d048fce0 0038fce0 2**5
CONTENTS, ALLOC, LOAD, READONLY, DATA
2 .data 0001e8bc d0592420 d0592420 00492420 2**5
CONTENTS, ALLOC, LOAD, DATA
3 .bss 000d1df0 d05b0ce0 d05b0ce0 004b0ce0 2**5
ALLOC
SYMBOL TABLE:
d0100120 l d .text 00000000
d048fce0 l d .rodata 00000000
d0592420 l d .data 00000000
(以下続く)
これ以外にも沢山のオプションが存在するので詳しくは man objdumpを参照。
readelfコマンド
readelfコマンドは、ELF Headerを読みその内容を画面に表示する。表示する内容は、ほぼobjdumpと同じだかELF形式のみでdisassemble機能などは無い。
readelfコマンドにも沢山のオプションがあるが、覚えるのが面倒なので、いつも-aオプションで全ての内容を表示させている。
# readelf -a /bsd.GENERIC
ELF Header:
Magic: 7f 45 4c 46 01 01 01 00 00 00 00 00 00 00 00 00
Class: ELF32
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: EXEC (Executable file)
Machine: Intel 80386
Version: 0x1
Entry point address: 0xd0100120
Start of program headers: 52 (bytes into file)
Start of section headers: 4918548 (bytes into file)
Flags: 0x0
Size of this header: 52 (bytes)
Size of program headers: 32 (bytes)
Number of program headers: 1
Size of section headers: 40 (bytes)
Number of section headers: 8
Section header string table index: 5
Section Headers:
[Nr] Name Type Addr Off Size ES Flg Lk Inf Al
[ 0] NULL 00000000 000000 000000 00 0 0 0
[ 1] .text PROGBITS d0100120 000120 38fba8 00 WAX 0 0 16
[ 2] .rodata PROGBITS d048fce0 38fce0 10273d 00 A 0 0 32
[ 3] .data PROGBITS d0592420 492420 01e8bc 00 WA 0 0 32
[ 4] .bss NOBITS d05b0ce0 4b0ce0 0d1df0 00 WA 0 0 32
[ 5] .shstrtab STRTAB 00000000 4b0ce0 000034 00 0 0 1
[ 6] .symtab SYMTAB 00000000 4b0e54 038480 10 7 8 4
[ 7] .strtab STRTAB 00000000 4e92d4 033123 00 0 0 1
Key to Flags:
W (write), A (alloc), X (execute), M (merge), S (strings)
I (info), L (link order), G (group), x (unknown)
O (extra OS processing required) o (OS specific), p (processor specific)
Program Headers:
Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align
LOAD 0x000120 0xd0100120 0xd0100120 0x4b0bbc 0x5829b0 RWE 0x20
Section to Segment mapping:
Segment Sections...
00 .text .rodata .data .bss
(以下続く)
readelfコマンドにはマニュアルが無いので、オプション無しでreadelfコマンドを実行すれば、オプション一覧を見ることが出来る。
Headerを調べるには、これらのコマンドを使用するのは便利ではあるが、怠けるとELF Headerの詳細が理解出来なくなりそうなので、load部分のプログラムを作成しながらHeader構造の解析を行ってみる事にする。
ELF Header
ELF Headerは、ELF FileのFile Offset 0の位置に常に存在し、32bit アーキテクチャと64bit アーキテクチャ用に別に定義されている。
このELF Headerの中には、Program HeaderとSection Headerが何処にどんなサイズで何個あるかと言う情報が書かれているので、ELFを扱うプログラムはこの情報を基に各Headerの読み込を行う。
ELF Headerの値
ELF Headerを読込む事は、それほど難しい事ではなく、次のような簡単なプログラムで行える。
int load_elf(const char *fname)
{
int fd;
Elf_Ehdr elf;
Elf_Shdr *shdr;
Elf_Phdr *phdr;
if ((fd = open(fname, 0)) < 0) {
printf("%s : File Open Error\n",fname);
return -1;
}
if ((read(fd, &elf, sizeof(Elf_Ehdr))) != sizeof(Elf_Ehdr)) {
puts("Error:ELF Header Read");
return -1;
}
このプログラムを使用して、OpenBSD 3.6 GENERIC Kernel(i386)のELF Headerを読込んだ場合、次の値になる。
OpenBSD 3.6 GENERIC Kernel(i386)のELF Header
| 構造体名 | メンバー名 | 詳細 |
|---|
| elf | e_ident[EI_NIDENT] | index | 値 | 内容 |
|---|
| EI_MAG0 | '\177' | マジックNO.0byte目 |
| EI_MAG1 | 'E' | マジックNO.1byte目 |
| EI_MAG2 | 'L' | マジックNO.2byte目 |
| EI_MAG3 | 'F' | マジックNO.3byte目 |
| EI_CLASS | ELFCLASS32 | バイナリファイルは32bit アーキテクチャ
ファイル空間と仮想アドレス空間が 4 ギガバイトまでのマシン |
| EI_DATA | ELFDATA2LSB| | プロセッサのバイトオーダーはリトルエンディアン |
| EI_VERSION | EV_CURRENT | ELFのHeader Versionはカレントバージョン |
| EI_OSABI | 0 (未使用?) | オペレーティングシステムとABIを識別 |
| EI_ABIVERSION | 0 (未使用?) | ABIのバージョンを識別 |
| EI_PAD | 0 | パディングの始め |
| 10-15 | 0 | 未定義(0 パディング) |
| e_type | ET_EXEC | オブジェクトファイルタイプが実行可能ファイル |
| e_machine | EM_386 | アーキテクチャはIntel 80386 |
| e_version | EV_CURRENT | ELFのFile Versionはカレントバージョン |
| e_entry | 0xD0100120 | プロセスを開始する仮想アドレス |
| e_phoff | 0x34 | プログラムヘッダテーブルが存在する場所のファイルオフセット値(byte) |
| e_shoff | 0x4B0D14 | セクションヘッダテーブルが存在する場所のファイルオフセット値(byte) |
| e_flags | 0x00 | ファイルに関連するプロセッサに固有なフラグ(未定義) |
| e_ehsize | 0x34 | ELF ヘッダのサイズ(byte) |
| e_phentsize | 0x20 | プログラムヘッダテーブルにあるエントリ 1個のサイズ |
| e_phnum | 0x01 | プログラムヘッダテーブル中のエントリの個数 |
| e_shentsize | 0x28 | セクションヘッダテーブルにあるエントリ 1個のサイズ |
| e_shnum | 0x08 | セクションヘッダテーブル中のエントリの個数 |
| e_shstrndx | 0x05 | セクションヘッダテーブルの、
セクション名文字列テーブルに結びつけられたエントリへのインデックス |
ELF Headerからの情報
- File情報
ELF Header中の最初4ByteはMagic NO.であり、ELF Fileであるならば"\177ELF"の値が入る。e_typeはファイルタイプを表し、このファイルが実行形式であることを示している。
- アーキテクチャ固有の情報
-
e_ident[EI_CLASS],e_ident[EI_DATA], e_machineの値から、このファイルはIntel 80386用のデータを格納していることが事がわかる。OpenBSDではProgram Headerを読込む前に、これらの値をチェックしているが、マジックNOとe_ident[EI_CLASS]だけを対象としている。
if (memcmp(elf.e_ident, ELFMAG, SELFMAG) != 0 ||
elf.e_ident[EI_CLASS] != ELFCLASS) {
puts("Read Error");
return -1;
}
- プロセス情報
e_entryにはこのプロセスが開始する仮想アドレスがセットされる。このKernelプロセスは、0xD0100120から始まる。
- Program Header
-
このファイルには、Program HeaderがFileの先頭から0x34 Byte目に1つ存在する。Program Headerのサイズは0x20 Byteである。
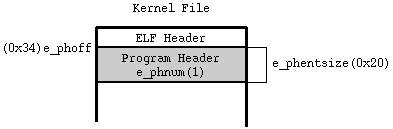
Program Header情報
- Section Header
-
このファイルには、Section HeaderがFileの先頭から0x4B0D14 Byte目に8つ存在する。それぞれのSection Header サイズは0x28 Byteである。
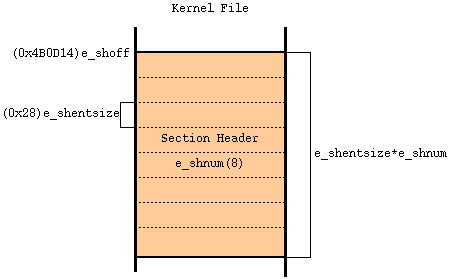
Section Header情報
- File上のHeader位置
-
ELF Headerの情報より下記のFile Mapになっていることがわかる。
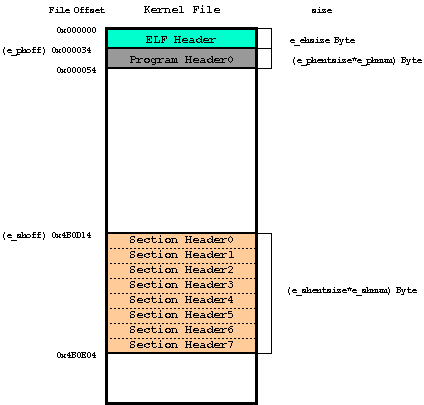
Kernel File上のHeader位置
Program Header
実行可能ファイルまたは共有オブジェクトファイルはProgram Headerを持つ。このHeaderはプログラム実行にシステムが必要とするセグメントなどの情報が定義されていて、ELF Headerと同じように32bit アーキテクチャと64bit アーキテクチャ用に別に定義されている。
Program Headerの値
Program Headerを読込むプログラムは次のようになる
if (lseek(fd, elf->e_phoff, SEEK_SET) == -1) {
puts("Error:lseek Program Header");
return -1;
}
sz = elf->e_phnum * sizeof(Elf_Phdr);
phdr = malloc(sz);
if (read(fd, phdr, sz) != sz) {
puts("Error:Read Program Headers");
return 1;
}
読出したProgram Headeの値は、次のようになる。
読込んだProgram Headerの内容
| 変数 | 値 | 詳細 |
|---|
| p_type | PT_LOAD | ロード可能なセグメント。 |
| p_offset | 0x120 | このセグメントが存在するファイルのオフセット。 |
| p_vaddr | 0xD0100120 | このセグメントの仮想アドレス。 |
| p_paddr | 0xD0100120 | 物理アドレッシング上の物理アドレス。 |
| p_filesz | 0x4B0BBC | セグメントのファイルイメージのバイト数をを示す。 |
| p_memsz | 0x5829B0 | セグメントのメモリイメージのバイト数を示す。 |
| p_flags | 0x07
(PF_X | PF_W | PF_R) | セグメントの属性を表すフラグ。(実行・書込・読取可) |
| p_align | 0x20 | セグメントのalignment値 |
Program Headerの情報
- セグメント属性
p_typeの値より、このセグメントはロード可能であり、p_flagsよりセグメントは実行・書込・読取可の属性を持っている事がわかる。
- セグメントの場所と大きさ
セグメントはファイルの先頭から0x120(p_offset) Byteの位置に存在し、その大きさは0x4B0BBC(p_filesz) Byteである。また、メモリ上に展開されたときの大きさは、0x5829B0(p_memsz) Byteの大きさになる。
- セグメントアドレス
このセグメントの仮想アドレス上の位置は、0xD0100120(p_vaddr)番地になり、メモリ中およびファイル中でセグメントは0x20(p_align)の倍数に整列される。
- File上のセグメント位置
-
Program Headerの情報より下記のFile Mapになっていることがわかる。
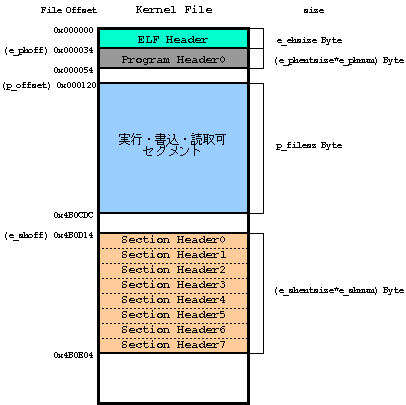
Kernel File 上のセグメント位置
- BSSの大きさ
-
セグメントによっては、ファイルイメージサイズを表す変数p_fileszとメモリ上のイメージサイズを表す変数p_memsが一致しないものがある。この差は何を意味するかというとBSSの領域となる。BSSは初期値を持たない変数の集まりなのでファイル上に領域を取っていてもDisk領域の無駄になるだけであり、論理的な差分として持っていた方が効率的になる。
| |
|
実行・書込・読取可
セグメント
<--- p_filesz --->
|
bss
|
|
|
|
<--------- p_memsz --------->
|
|
|
システム ローダーは、p_memsとp_fileszの差分を求め、これをBSSとしてメモリ上に作成する事になる。
他OSのProgram Header
OpenBSDのProgram Headerを眺めて驚いたのは、セグメントが「書込不可の属性」と「実行不可の属性」に別れておらず、1つのセグメントに一緒になっていたことだ。最初に浮かんだ疑問は「他のOSはどうなってんだろう?」と言うことだったので調べてみた。
NetBSDのProgram Header
NetBSD 2.0 (GENERIC)のProgram Headerをreadelfコマンドで表示させると次のようになる。
# readelf -l netbsd-GENERIC
Elf file type is EXEC (Executable file)
Entry point 0xc0100000
There are 2 program headers, starting at offset 52
Program Headers:
Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align
LOAD 0x001000 0xc0100000 0xc0100000 0x6496a8 0x6496a8 R E 0x1000
LOAD 0x64a6c0 0xc074a6c0 0xc074a6c0 0x2406c 0x9c1dc RW 0x1000
Section to Segment mapping:
Segment Sections...
00 .text .rodata .rodata.str1.1 .rodata.str1.32 link_set_malloc_types link_set_sysctl_funcs link_set_evcnts
01 .data .bss
Segment0は書込不可の属性を持っていて、.text .rodata などがマッピングされている。Segment1は実行不可の属性を持っていて、.data .bss などがマッピングされている。a.out時のOpenBSDはこのようなセグメント構成だった気がする...
2. FreeBSDのProgram Header
FreeBSD 4.8のProgram Headerをreadelfコマンドで表示させると次のようになる。
# readelf -l -W /kernel.GENERIC
Elf file type is EXEC (Executable file)
Entry point 0xc0128320
There are 5 program headers, starting at offset 52
Program Headers:
Type Offset VirtAddr PhysAddr FileSiz MemSiz Flg Align
PHDR 0x000034 0xc0100034 0xc0100034 0x000a0 0x000a0 R E 0x4
INTERP 0x0000d4 0xc01000d4 0xc01000d4 0x0000d 0x0000d R 0x1
[Requesting program interpreter: /red/herring]
LOAD 0x000000 0xc0100000 0xc0100000 0x29c035 0x29c035 R E 0x1000
LOAD 0x29c040 0xc039d040 0xc039d040 0x43d48 0x65b54 RW 0x1000
DYNAMIC 0x2dfd48 0xc03e0d48 0xc03e0d48 0x00040 0x00040 RW 0x4
Section to Segment mapping:
Segment Sections...
00
01 .interp
02 .interp .hash .dynsym .dynstr .text .rodata
03 .data .set.cons_set .set.kbddriver_set .set.periphdriver_set
.set.scrndr_set .set.scterm_set .set.sysctl_set .set.sysinit_set .set.sysuninit_set
.set.vga_set .set.videodriver_set .got .dynamic .bss
04 .dynamic
Headerの数が異様に多いが、やはり.text .rodata と.data .bssは明確に別れている。
なぜOpenBSDが1つのセグメントに.text .rodata .data .bssを一緒にまとめるようなアプローチを取っているのかは不明だが、同じBSDでもProgram Headerの構成がかなり異なるのは興味深い事だ。
Section Header
Section Headerは、ファイルのSectionの位置決定を可能する。各Sectionにはプログラムコードや読取り専用データ、読書き可能データ、再配置エントリー、シンボル等の情報が種類ごとに格納されている。
Section Headerの情報は、kernel実行時に特に必要としない。しかしKernel Loaderは、これを読込みメモリー上に情報を展開する。これは、ddbと呼ばれるkernel debuggerがシンボル情報を使用するためであり、kernelがpanicになりddbに落ちたり、Ctl-Alt-Escで明示的にddbに落とした時に、いつでもシンボル情報を読めるようにしておくためである。
Kernel panic時にddbに落とすようにするには、/etc/sysctl.confにあるddb.panicを1にセットする
Ctl-Alt-Escで明示的にddbに落とすようにするには、ddb.consoleを1にセットする
ddb.panic=1 # 0=Do not drop into ddb on a kernel panic
ddb.console=1 # 1=Permit entry of ddb from the console
Section Headerの値
Section Headerを読込むプログラムは次のようになる
if (lseek(fd, elf->e_shoff, SEEK_SET) == -1) {
puts("lseek section headers");
return 1;
}
sz = elf->e_shnum * sizeof(Elf_Shdr);
shdr = malloc(sz);
if (read(fd, shdr, sz) != sz) {
puts("read section headers");
return 1;
}
読出した値は、次のようになる。
| 構造体名 | 変数 | shdr[0] | shdr[1] | shdr[2] | shdr[3] |
|---|
| shdr | sh_name | 0x0 | 0x1B | 0x21 | 0x29 |
|---|
| sh_type | SHT_NULL | SHT_PROGBITS | SHT_PROGBITS | SHT_PROGBITS |
| sh_flags | 0x0 | 0x7 | 0x2 | 0x3 |
| sh_addr | 0x0 | 0xD0100120 | 0xD048FCE0 | 0xD0592420 |
| sh_offset | 0x0 | 0x120 | 0x38FCE0 | 0x492420 |
| sh_size | 0x0 | 0x38FBA8 | 0x10273D | 0x1E8BC |
| sh_link | 0x0 | 0x0 | 0x0 | 0x0 |
| sh_info | 0x0 | 0x0 | 0x0 | 0x0 |
| sh_addralign | 0x0 | 0x10 | 0x20 | 0x20 |
| sh_entsize | 0x0 | 0x0 | 0x0 | 0x0 |
| 構造体名 | 変数 | shdr[4] | shdr[5] | shdr[6] | shdr[7] |
|---|
| shdr | sh_name | 0x2F | 0x11 | 0x1 | 0x9 |
|---|
| sh_type | SHT_NOBITS | SHT_STRTAB | SHT_SYMTAB | SHT_STRTAB |
| sh_flags | 0x3 | 0x0 | 0x0 | 0x0 |
| sh_addr | 0xD05B0CE0 | 0x0 | 0x0 | 0x0 |
| sh_offset | 0x4B0CE0 | 0x4B0CE0 | 0x4B0E54 | 0x4E92D4 |
| sh_size | 0xD1DF0 | 0x34 | 0x38480 | 0x33123 |
| sh_link | 0x0 | 0x0 | 0x7 | 0x0 |
| sh_info | 0x0 | 0x0 | 0x8 | 0x0 |
| sh_addralign | 0x20 | 0x1 | 0x4 | 0x1 |
| sh_entsize | 0x0 | 0x0 | 0x10 | 0x0 |
ELF Headerからの情報
- Section名
-
sh_nameにセットされている値は、String Tableのoffset値であり、その先にはSectionの名前が格納されている。
例えば、Section Header4のSection名を参照する場合は下図のようになる。ELF Headerのe_shstrndxには、Section Headerのインデックス値がセットされている。インデックス先のSection Header(ソースコード上ではshdr[5])には、String Tableが存在するFile Offsetがセットされている。
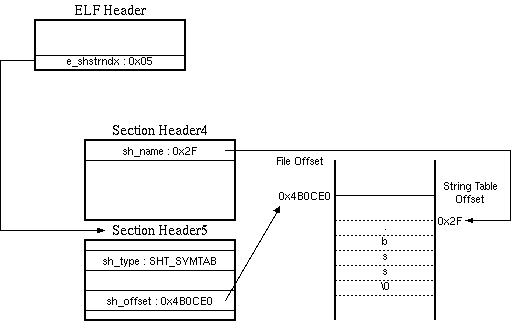
Section名の参照
Section Header4のSection名は、そのString Tableからshdr[4]->sh_name Byteの位置にあり、文字列の終端(\0)までがSection名となる。
- Section属性
sh_typeはSectionの内容を表し、sh_flagsは複数の属性をbitで表す。
- アドレス情報
sh_addはセクションがメモリ上に現れるアドレスを表す。
- Sectionの実体
sh_offsetはセクションのファイル先頭からのバイトオフセットを表す。またsh_sizeは、セクションのバイトでの大きさを表す。
- File上のSection位置
-
Section Headerの情報より下記のFile Mapになっていることがわかる。
Section Header0のsh_typeはSHT_NULLがセットされているので無効なSection情報になる。また、Section Header4のsh_typeはSHT_NOBITSがセットされているので、file上に実体を持たないSectionである。
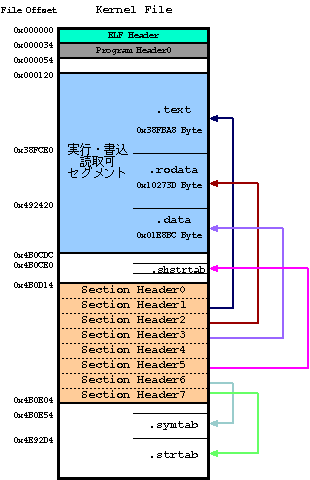
Kernel File上のSection位置
Symbol TableとString Table
Symbol Tableは、プログラムのSymbol定義と参照の位置決定に必要な情報がセットされている。String Tableは、ヌル文字で終わる文字の羅列で構成されており、それぞれのシンボルはヌル文字で区切られる。
Kernel LoaderはKernelを読込んだ後、Symbol TableとString TableをKernelの後ろに追加する。これらの情報は実行時には使用されないが、panic時に移行するDebug modeに入った時にdebuggerが使用する事になるだろう。
Last modified: Sat Jan 26 16:50:10 2008 JST